Criar um Api em Spring Boot usando Selenium para fazer scraping de uma página da web

Neste tutorial, você verá:
✔️ Inicializa um serviço de scraping com Selenium.
✔️ Acessa uma página de exemplo (https://example.com).
✔️ Obtém o título da página e imprime no console.
📌 Simplifique seu processo de deploy com o nosso painel ICP!
Hoje, vamos criar um exemplo completo de como usar Selenium com Spring Boot 3 para fazer scraping de uma página da web. O projeto usa WebDriverManager para gerenciar o ChromeDriver automaticamente.
📌 Passo 1: Criar o Projeto Spring Boot
Crie um novo projeto Spring Boot 3 no Spring Initializr ( https://start.spring.io/ ) :
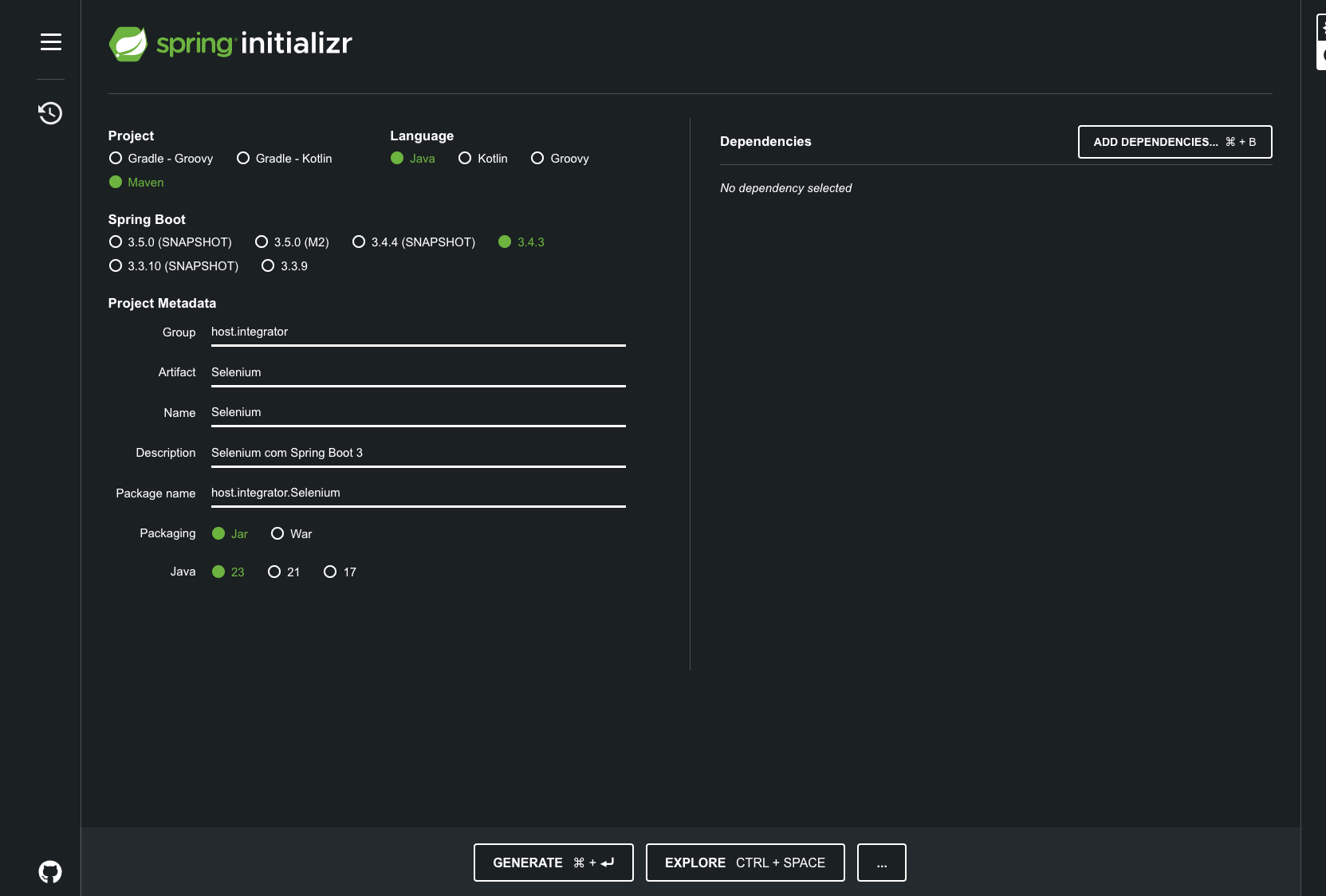
📌 Passo 2: Estrutura do Projeto:
A estrutura do projeto ficará assim:
spring-boot-selenium-scraper/
│── src/
│ ├── main/
│ │ ├── java/host/integrator/scraper/
│ │ │ ├── ScraperApplication.java # Classe principal do Spring Boot
│ │ │ ├── controller/
│ │ │ │ ├── ScraperController.java # Controller para expor o scraping via API
│ │ │ ├── service/
│ │ │ │ ├── ScraperService.java # Serviço que executa o Selenium WebDriver
│ │ ├── resources/
│ │ │ ├── application.properties # Configurações do Spring Boot (se necessário)
│ ├── test/ # Testes unitários (opcional)
│── pom.xml # Dependências Maven
│── README.md # Documentação do projeto
📌 Passo 3: Adicione as dependências ao pom.xml
<dependencies>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Selenium -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.15.0</version>
</dependency>
<!-- WebDriverManager para gerenciar o ChromeDriver -->
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>5.6.2</version>
</dependency>
</dependencies>📌 Passo 4: Crie um serviço para scraping (ScraperService.java)
package host.integrator.Selenium.service;
import io.github.bonigarcia.wdm.WebDriverManager;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.springframework.stereotype.Service;
@Service
public class ScraperService {
public String scrapeTitle(String url) {
// Configurar o ChromeDriver automaticamente
WebDriverManager.chromedriver().setup();
// Configurar o ChromeDriver no modo headless
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless", "--disable-gpu"); // Rodar sem interface gráfica
options.addArguments("--no-sandbox"); // Recomendado para evitar problemas de permissão
options.addArguments("--disable-dev-shm-usage"); // Melhora a performance em containers
// Inicializa o WebDriver com as opções definidas
WebDriver driver = new ChromeDriver(options);
try {
driver.get(url);
return driver.getTitle(); // Obtém o título da página
} finally {
driver.quit(); // Fecha o navegador
}
}
}
📌 Passo 5: Crie um Controller para expor o scraping via API (ScraperController.java)
package host.integrator.Selenium.controller;
import host.integrator.Selenium.service.ScraperService;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ScraperController {
private final ScraperService scraperService;
public ScraperController(ScraperService scraperService) {
this.scraperService = scraperService;
}
@GetMapping("/scrape")
public String scrape(@RequestParam String url) {
return scraperService.scrapeTitle(url);
}
}
📌 Passo 6: Testando a API
Inicie o Spring Boot e faça a seguinte requisição:
curl -X GET "http://localhost:8080/scrape?url=https://integrator.host"
Temos o resultado:



